前两天看到腾讯推出一个个人知识库产品 ima,融合了 DeepSeek,可以直接搜索知识库中的内容,还可以上传文档回答,所以今天就来体验一下这个新产品 ima。
ima 是什么
ima 官方给出的定位是「会思考的知识库」,首先它是一个知识库,并且看官方还是一个跨平台,多端支持的知识库,包括了 macOS,Windows,iOS,Android,以及小程序。会思考则是体现在它接入了 AI,腾讯自己的混元大语言模型,和 DeepSeek R1 模型。
| YouTube | Bilibili |
功能
公众号搜索
让我非常惊喜的是 ima 侧边栏可以直接进行公众号的全文检索。在侧边栏搜索的时候,可以快速将公众号的内容作为资料参考来源。
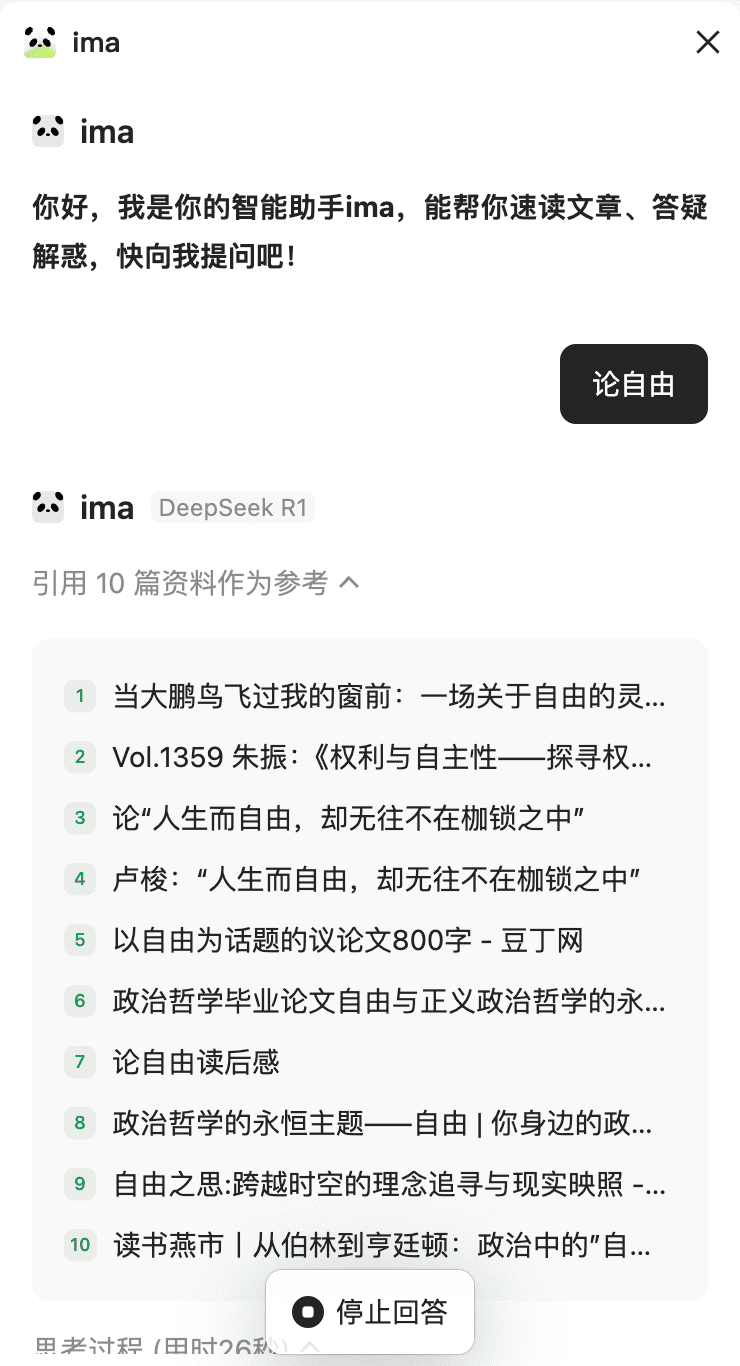
上传文档
ima 提供了知识库管理,用户可以直接上传文档,或者将网页内容存放到知识库中。知识库也可以作为分享,以链接或者二维码方式分享给其他人。
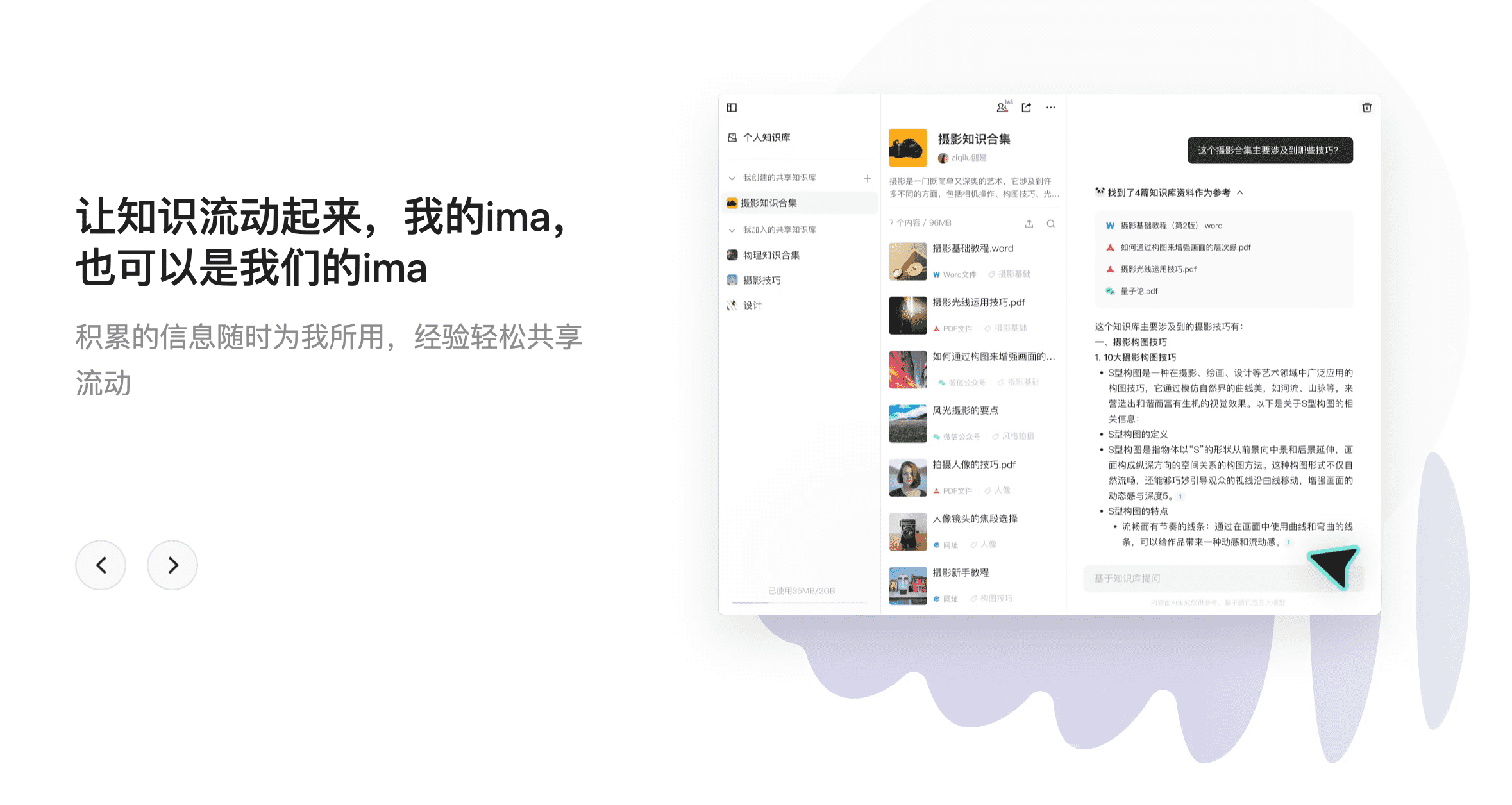
个人笔记知识库
用户可以将自己的笔记存放到知识库中,也可以将知识库分享给其他人,知识库支持 Markdown 格式。
文章文案生成
ima 预置了一些模板,用户可以根据模板生成文章文案,也可以自定义生成文章文案。
支持论文,作文,朋友圈,小红书文案等等。

注意事项
ima 目前的方案都是在线的,官方给出了 2GB 的云端存储空间,也就意味着用户可以上传至多 2GB 的文件,未来不排除可能会按照容量进行收费。另外在我自己的尝试过程中,发现 ima 目前的回答速度和文章编写速度都还是非常慢的,相比于目前我自己的使用 [[Perplexity]] ,Claude,ChatGPT 等。但是令我惊喜的是 ima 的大语言模型可以直接检索公众号的内容,虽然公众号的内容也是良莠不齐,但是这么庞大的数据以前很少可以作为检索结果直接出现在搜索结果中,如果对公众号的内容依赖比较重的话,不妨也可以尝试一下 ima。
另外这两天 X 也公开了 Grok3,并且可以直接返回 X 上的内容,而豆包也可以检索抖音上的视频,ima 作为腾讯旗下的产品也可以检索微信公众号的内容,但很可惜的是他们虽然借助互联网发展壮大了,但数据却停留在了一道隐形的围墙之中,Google 拥有如此庞大的搜索数据,和非常庞大的 UGC 视频站 YouTube,但在 AI 上却还是一直再追赶,或许是某种谨慎,也或许是想探索更多的可能性,直接利用用户的数据进行模型训练,或者作为模型参考数据来源,到底是否是一种正确的方向,还有待时间来验证。但是 Google 内部小团队发布的 NotebookLM,Learn About ,还有 Whisk 等等,每一步都做的非常小心,我觉得这一点还挺值得尊敬的。